Crunching Function for XlsForm
Source:vignettes/crunching-function-for-xlsform.Rmd
crunching-function-for-xlsform.RmdPreparing objects
Data loading
datalist <- kobo_data(datapath = system.file("data.xlsx", package = "kobocruncher") )
# MainFrame
datalist[["main"]]
#> # A tibble: 5 × 26
#> start end location profile.country
#> <dttm> <dttm> <chr> <chr>
#> 1 2022-10-27 08:57:57 2022-11-10 08:49:09 private_facility VEN
#> 2 2022-10-24 11:36:52 2022-10-24 15:46:00 home HND
#> 3 2022-10-26 16:19:35 2022-10-26 18:15:07 subcenter SLV
#> 4 2022-10-26 16:19:35 2022-10-26 17:51:14 subcenter SLV
#> 5 2022-10-26 14:02:06 2022-10-26 16:10:25 home COL
#> # ℹ 22 more variables: profile.occupation <chr>, profile.reason <chr>,
#> # profile.reason.accomodation <dbl>, profile.reason.employment <dbl>,
#> # profile.reason.education <dbl>, profile.reason.community <dbl>,
#> # profile.reason.safety <dbl>, profile.reason.movement <dbl>,
#> # profile.reason.reunification <dbl>, profile.reason.no_answer <dbl>,
#> # profile.reason.other <dbl>, profile.HHSize <dbl>, `_id` <dbl>,
#> # `_uuid` <chr>, `_submission_time` <dbl>, `_validation_status` <lgl>, …
# Second Frame - based on presence of repeat within the form, aka nested or
# hierarchical data structure, etc...
datalist[["members"]]
#> # A tibble: 12 × 14
#> members.age members.sex `_index` `_parent_table_name` `_parent_index`
#> <dbl> <chr> <dbl> <chr> <dbl>
#> 1 56 male 1 Sample Dataset KoboloadeR 1
#> 2 2 male 2 Sample Dataset KoboloadeR 2
#> 3 3 male 3 Sample Dataset KoboloadeR 2
#> 4 10 female 4 Sample Dataset KoboloadeR 2
#> 5 45 male 5 Sample Dataset KoboloadeR 2
#> 6 35 female 6 Sample Dataset KoboloadeR 2
#> 7 4 male 7 Sample Dataset KoboloadeR 3
#> 8 34 female 8 Sample Dataset KoboloadeR 3
#> 9 34 male 9 Sample Dataset KoboloadeR 3
#> 10 51 female 10 Sample Dataset KoboloadeR 4
#> 11 21 male 11 Sample Dataset KoboloadeR 5
#> 12 25 female 12 Sample Dataset KoboloadeR 5
#> # ℹ 9 more variables: `_submission__id` <dbl>, `_submission__uuid` <chr>,
#> # `_submission__submission_time` <dbl>,
#> # `_submission__validation_status` <lgl>, `_submission__notes` <lgl>,
#> # `_submission__status` <chr>, `_submission__submitted_by` <lgl>,
#> # `_submission__tags` <lgl>, parent_index <dbl>Extend the xlsform to add instructions for the analysis plan
Now we can extend the xlsform that was used to document key next steps in the data preparation.
kobo_prepare_form(xlsformpath = system.file("form.xlsx", package = "kobocruncher"),
xlsformpathout = NULL,
label_language = "")
#> [1] "There was an error in the xlsform preparation step!!! \n\n"
#> $message
#> [1] "`path` does not exist: ''"
#>
#> $call
#> NULL
#>
#> attr(,"class")
#> [1] "try-error"Prepare data dictionnary
dico <- kobo_dico( xlsformpath = system.file("sample_xlsform.xlsx", package = "kobocruncher") )
# Survey
questions <- as.data.frame(dico[["variables"]])
knitr::kable(utils::head(questions, 10))| type | list_name | name | label | hint | name_or | repeatvar | scope | chapter | subchapter | disaggregation | correlate | appearance |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| today | NA | today | NA | NA | today | main | NA | NA | NA | NA | ||
| date | NA | date | Interview date | this is a hint | date | main | NA | NA | NA | NA | ||
| select_one | location | location | Where is the interview taking place | this is a hint | location | main | NA | NA | NA | NA | ||
| begin_group | NA | profile.profile | Respondant profile | NA | profile | main | profile | NA | NA | NA | NA | |
| select_one | countries | profile.country | What is your country of Origin? | this is a hint | country | main | profile | NA | NA | NA | NA | |
| text | NA | profile.occupation | What’s you occupation? | this is a hint | occupation | main | profile | NA | NA | NA | NA | |
| select_multiple | reasons | profile.reason | Why did you left? | this is a hint | reason | main | profile | NA | NA | NA | NA | |
| integer | NA | profile.HHSize | What’s the size of your household? | this is a hint | HHSize | main | profile | NA | NA | NA | NA | |
| end_group | NA | NA | NA | NA | NA | main | NA | NA | NA | NA | ||
| begin_repeat | NA | members.members | Please enter information for each family member | NA | members | members | members | NA | NA | NA | NA |
# Choices
responses <- as.data.frame(dico[["modalities"]])
knitr::kable(utils::head(responses, 10))| list_name | name | label | order |
|---|---|---|---|
| location | home | Home | NA |
| location | subcenter | Community Center | NA |
| location | private_facility | Private facility | NA |
| sex | male | Male | NA |
| sex | female | Female | NA |
| countries | COL | Colombia | NA |
| countries | CUB | Cuba | NA |
| countries | SLV | El Salvador | NA |
| countries | GTM | Guatemala | NA |
| countries | HND | Honduras | NA |
# Settings
metadata <- as.data.frame(dico[["settings"]])
knitr::kable(utils::head(metadata, 10))| form_title | form_id |
|---|---|
| Sample Dataset KoboloadeR | koboloadeR |
# Report ToC
toc <- as.data.frame(dico[["plan"]])
knitr::kable(utils::head(toc, 10))| type | label | name |
|---|---|---|
| today | NA | today |
| date | Interview date | date |
| select_one | Where is the interview taking place | location |
| begin_group | Respondant profile | profile.profile |
| select_one | What is your country of Origin? | profile.country |
| text | What’s you occupation? | profile.occupation |
| select_multiple | Why did you left? | profile.reason |
| integer | What’s the size of your household? | profile.HHSize |
| begin_repeat | Please enter information for each family member | members.members |
| integer | Age | members.age |
# Indicator
indicator <- as.data.frame(dico[["indicator"]])
knitr::kable(utils::head(indicator, 10))| type | name | label | list_name | hint | repeatvar | calculation | chapter | subchapter | disaggregation | correlate | cluster | predict | score | mappoint | mappoly |
|---|
Data Processing
Indicator Calculation
Indicator calculation
xlsformpath <- system.file("sample_xlsform.xlsx", package = "kobocruncher")
xlsformpathout <- paste0(tempdir(),"/", "sample_xlsform_withindic.xlsx")
dico <- kobo_dico( xlsformpath = system.file("sample_xlsform.xlsx", package = "kobocruncher") )
datalist <- kobo_data(datapath = system.file("data.xlsx", package = "kobocruncher") )
## Check if we add no indicator
expanded <- kobo_indicator(datalist = datalist,
dico = dico,
indicatoradd = NULL ,
xlsformpath = xlsformpath,
xlsformpathout = xlsformpathout)
#> no calculated indicators has been defined...
## Example 1: Simple dummy filter
indicatoradd <- c( name = "inColombia",
type = "select_one",
label = "Is from Colombia",
repeatvar = "main",
calculation = "dplyr::if_else(datalist[[\"main\"]]$profile.country ==
\"COL\", \"yes\",\"no\")")
expanded <- kobo_indicator(datalist = datalist,
dico = dico,
indicatoradd = indicatoradd ,
xlsformpath = xlsformpath,
xlsformpathout = xlsformpathout)
## Replace existing
dico <- expanded[["dico"]]
datalist <- expanded[["datalist"]]
## Check my new indicator
table(datalist[[1]]$inColombia, useNA = "ifany")
#>
#> no yes
#> 4 1
## Example 2: calculation on nested elements and build an indicator list
indicatoradd2 <- c( name = "hasfemalemembers",
type = "select_one",
label = "HH has female members ",
repeatvar = "main",
calculation = "datalist[[\"members\"]] |>
dplyr::select( members.sex, parent_index) |>
tidyr::gather( parent_index, members.sex) |>
dplyr::count(parent_index, members.sex) |>
tidyr::spread(members.sex, n, fill = 0) |>
dplyr::select( female)")
indicatorall <- list(indicatoradd, indicatoradd2 )
expanded <- kobo_indicator(datalist = datalist,
dico = dico,
indicatoradd = indicatorall ,
xlsformpath = xlsformpath,
xlsformpathout = xlsformpathout)
## Replace existing
dico <- expanded[["dico"]]
datalist <- expanded[["datalist"]]
## Check my new indicator
table(datalist[[1]]$hasfemalemembers, useNA = "ifany")
#> female
#> 0 1 2
#> 1 3 1
# Example of calculations:
#
# 1. Create a filters on specific criteria
# 'dplyr::if_else(datalist[["main"]]$variable =="criteria", "yes","no")'
#
#
# 2. Ratio between 2 numeric variable
# 'datalist[["main"]]$varnum1 / datalist[["main"]]$varnum2'
#
#
# 3. Calculation on date - month between data and now calculated in months
# 'lubridate::interval( datalist[["main"]]$datetocheck,
# lubridate::today()) %/% months(1)'
#
# 4. Discretization of numeric variable according to quintile
# 'Hmisc::cut2(datalist[["main"]]$varnum, g =5)'
#
# 5. Discretization of numeric variable according to fixed break -
# for instance case size from integer to categoric
# 'cut(datalist[["main"]]$casesize, breaks = c(0, 1, 2, 3,5,30),
# labels = c("Case.size.1", "Case.size.2", "Case.size.3",
# "Case.size.4.5", "Case.size.6.or.more" ), include.lowest=TRUE)'
#
# 6. Aggregate variable from nested frame (aka within repeat) to parent table
# 'datalist[["members"]] |>
# dplyr::select( members.sex, parent_index) |>
# tidyr::gather( parent_index, members.sex) |>
# dplyr::count(parent_index, members.sex) |>
# tidyr::spread(members.sex, n, fill = 0) |>
# dplyr::select( female)'
Assess Disclosure Risk
to do….
# dico <- kobo_dico( xlsformpath = system.file("sample_xlsform.xlsx", package = "kobocruncher") )
# datalist <- kobo_data(datapath = system.file("data.xlsx", package = "kobocruncher") )
#
# kobo_anonymise(datalist = datalist,
# dico = dico,
# indicatoradd = indicatoradd )
Labeling functions
Get the correct frame for a specific variable
dico <- kobo_dico( xlsformpath = system.file("sample_xlsform.xlsx", package = "kobocruncher") )
datalist <- kobo_data(datapath = system.file("data.xlsx", package = "kobocruncher") )
data <- kobo_frame(datalist = datalist,
dico = dico,
var = "members.sex" )
knitr::kable(utils::head(data,5))| members.age | members.sex | _index | _parent_table_name | _parent_index | _submission__id | _submission__uuid | _submission__submission_time | _submission__validation_status | _submission__notes | _submission__status | _submission__submitted_by | _submission__tags | parent_index | X_id |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 56 | male | 1 | Sample Dataset KoboloadeR | 1 | 20759478 | 48cc75b7-3d86-4c3e-a99b-24b4032b7b9c | 44685.89 | NA | NA | submitted_via_web | NA | NA | 1 | 1 |
| 2 | male | 2 | Sample Dataset KoboloadeR | 2 | 20756978 | f1c3d36c-3c25-4581-9f35-9c8ec405d744 | 44685.84 | NA | NA | submitted_via_web | NA | NA | 2 | 2 |
| 3 | male | 3 | Sample Dataset KoboloadeR | 2 | 20756978 | f1c3d36c-3c25-4581-9f35-9c8ec405d744 | 44685.84 | NA | NA | submitted_via_web | NA | NA | 2 | 3 |
| 10 | female | 4 | Sample Dataset KoboloadeR | 2 | 20756978 | f1c3d36c-3c25-4581-9f35-9c8ec405d744 | 44685.84 | NA | NA | submitted_via_web | NA | NA | 2 | 4 |
| 45 | male | 5 | Sample Dataset KoboloadeR | 2 | 20756978 | f1c3d36c-3c25-4581-9f35-9c8ec405d744 | 44685.84 | NA | NA | submitted_via_web | NA | NA | 2 | 5 |
Get the label for a specific variable
dico <- kobo_dico( xlsformpath = system.file("sample_xlsform.xlsx", package = "kobocruncher") )
label_varname(dico = dico,
x ="profile.country")
#> [1] "What is your country of Origin?"Get interpretation hint for a specific variable
dico <- kobo_dico( xlsformpath = system.file("sample_xlsform.xlsx", package = "kobocruncher") )
label_varhint(dico = dico,
x ="profile.country")
#> [1] "this is a hint"Get all the choices labels options for a specific variable
dico <- kobo_dico( xlsformpath = system.file("sample_xlsform.xlsx", package = "kobocruncher") )
datalist <- kobo_data(datapath = system.file("data.xlsx", package = "kobocruncher") )
data <- kobo_frame(datalist = datalist,
dico = dico,
var = "profile.country" )
label_choiceset(dico = dico,
x="profile.country")(data$profile.country)
#> VEN HND SLV SLV COL
#> "Venezuela" "Honduras" "El Salvador" "El Salvador" "Colombia"
## Test when there's no dictionnary
data$profile.occupation
#> [1] "Consultant" "farmer" "vendor" "teacher" "farmer"
label_choiceset(dico = dico,
x="profile.occupation")(data$profile.occupation)
#> <NA> <NA> <NA> <NA> <NA>
#> "Consultant" "farmer" "vendor" "teacher" "farmer"
label_choiceset(dico = dico,
x="profile.occupation")(data$profile.occupation)
#> <NA> <NA> <NA> <NA> <NA>
#> "Consultant" "farmer" "vendor" "teacher" "farmer"Plotting Functions
Plotting Select one variable
dico <- kobo_dico( xlsformpath = system.file("sample_xlsform.xlsx", package = "kobocruncher") )
datalist <- kobo_data(datapath = system.file("data.xlsx", package = "kobocruncher") )
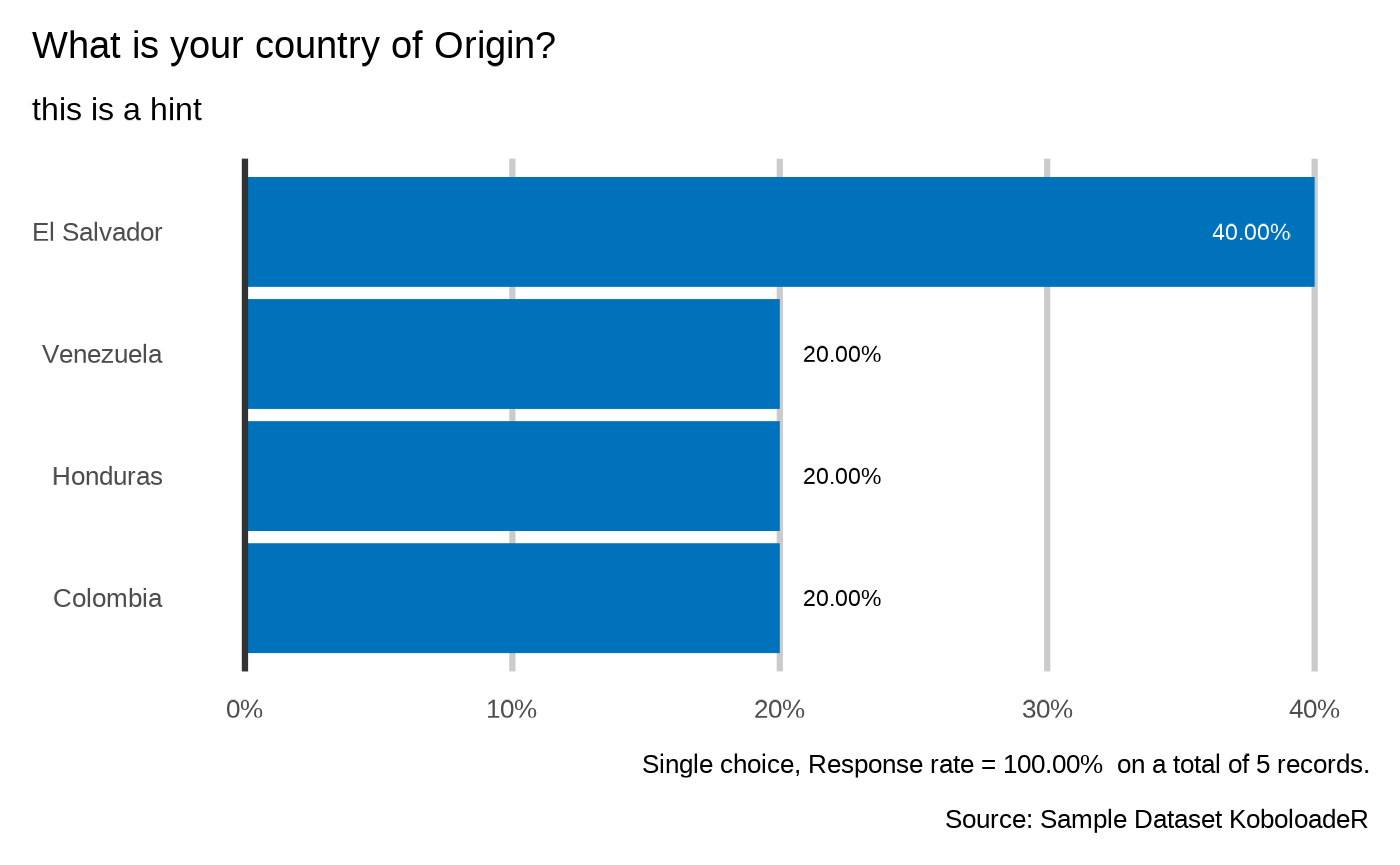
plot_select_one(datalist = datalist,
dico = dico,
var = "profile.country",
showcode = TRUE)
#>
#> What is your country of Origin?
#> `plot_select_one(datalist, dico, "profile.country", datasource = params$datasource, n = 4)`
#>
#> 
## Exmaple with lumping
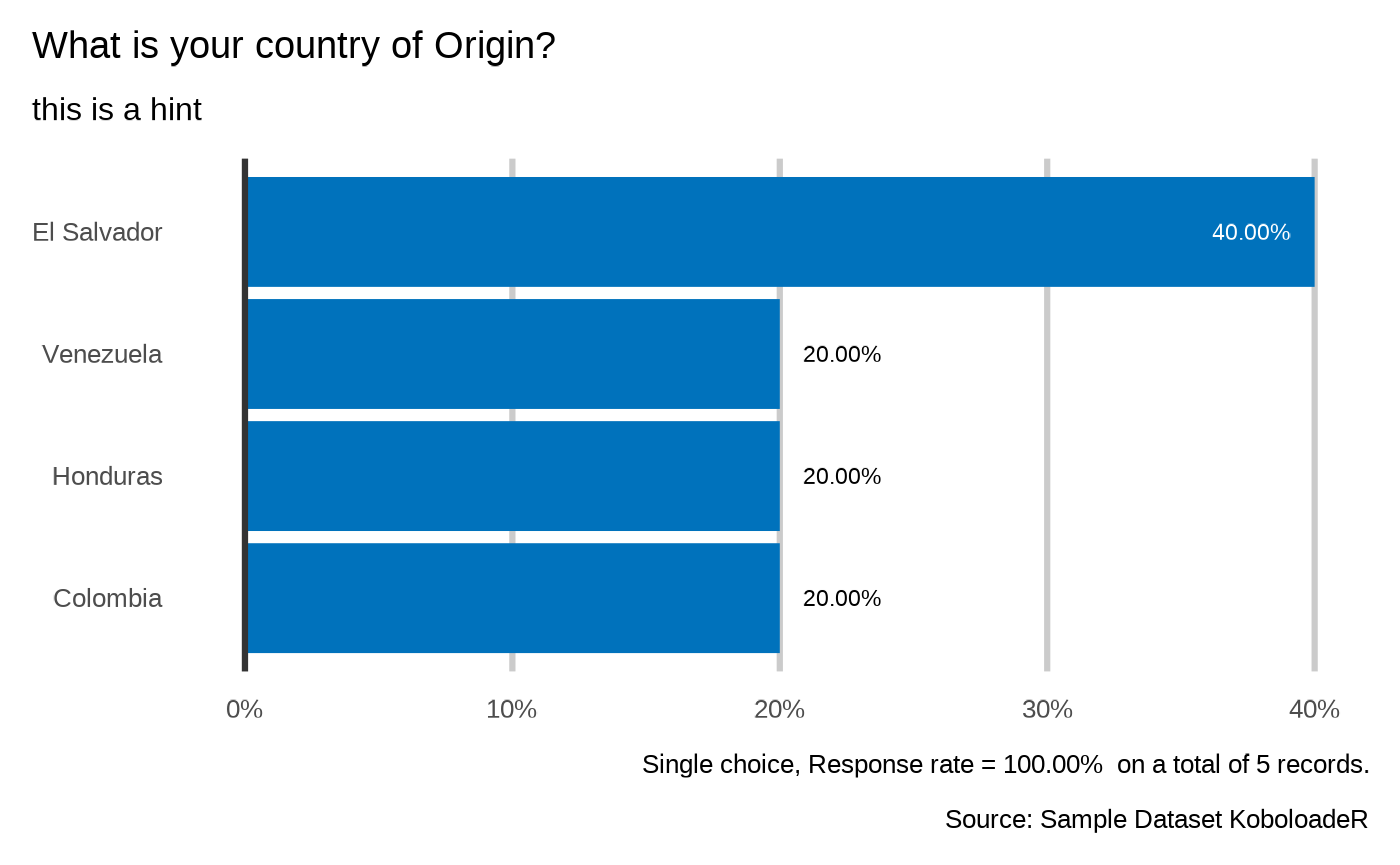
plot_select_one(datalist = datalist,
dico = dico,
var = "profile.country",
n = 1,
showcode = TRUE)
#>
#> What is your country of Origin?
#> `plot_select_one(datalist, dico, "profile.country", datasource = params$datasource, n = 1)`
#>
#> 
# plot_select_one(datalist = datalist,
# dico = dico,
# var = "profile.countryerror",
# showcode = TRUE)Plotting Select multiple variable
dico <- kobo_dico( xlsformpath = system.file("sample_xlsform.xlsx", package = "kobocruncher") )
datalist <- kobo_data(datapath = system.file("data.xlsx", package = "kobocruncher") )
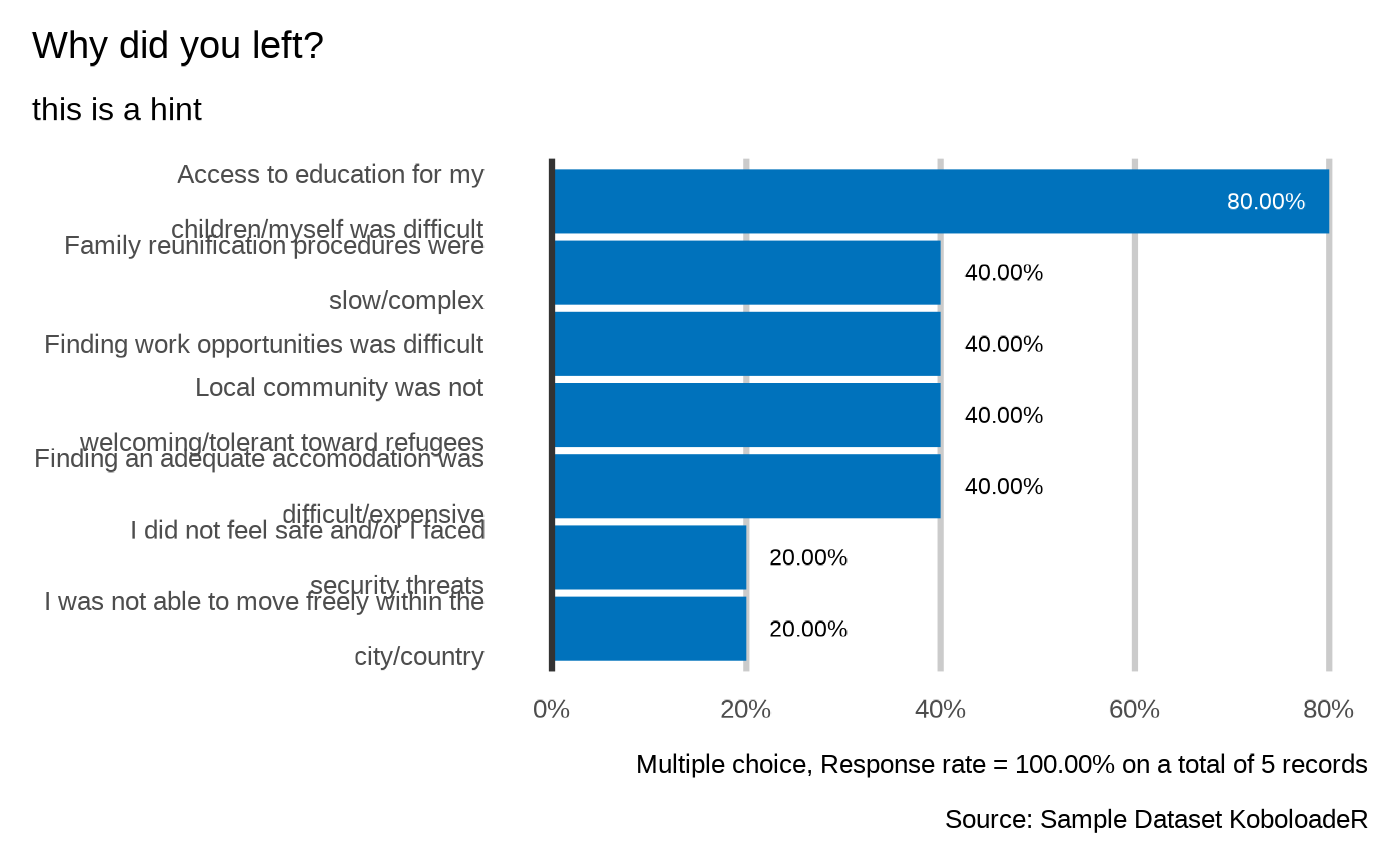
plot_select_multiple(datalist = datalist,
dico = dico,
var = "profile.reason",
datasource = NULL,
showcode = TRUE
)
#> Why did you left?
#> `plot_select_multiple(datalist, dico, "profile.reason", datasource=params$datasource, n=7)`
#>
#> 
## Displaying the usage of the lumping option..
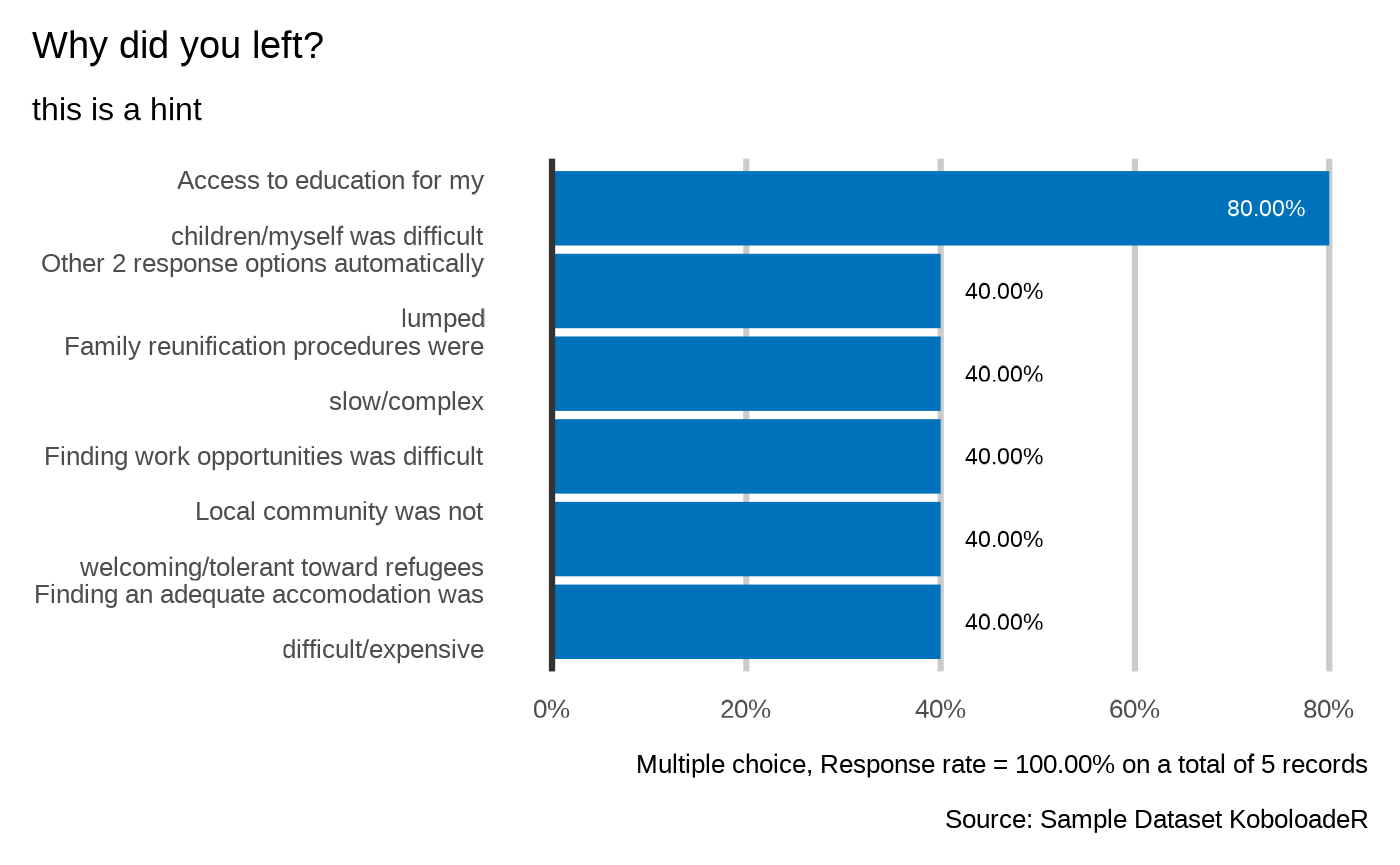
plot_select_multiple(datalist = datalist,
dico = dico,
var = "profile.reason",
n = 5,
datasource = NULL,
showcode = TRUE
)
#> Why did you left?
#> `plot_select_multiple(datalist, dico, "profile.reason", datasource=params$datasource, n=5)`
#>
#> 
# plot_select_multiple(datalist = datalist,
# dico = dico,
# var = "profile.reason1",
# showcode = TRUE
# )Plotting Numeric variable
dico <- kobo_dico( xlsformpath = system.file("sample_xlsform.xlsx", package = "kobocruncher") )
datalist <- kobo_data(datapath = system.file("data.xlsx", package = "kobocruncher") )
plot_integer(datalist = datalist,
dico = dico,
var = "members.age",
showcode = TRUE)
#> Age
#> `plot_integer(datalist, dico, "members.age", datasource=params$datasource)`
#>
#>
#> `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.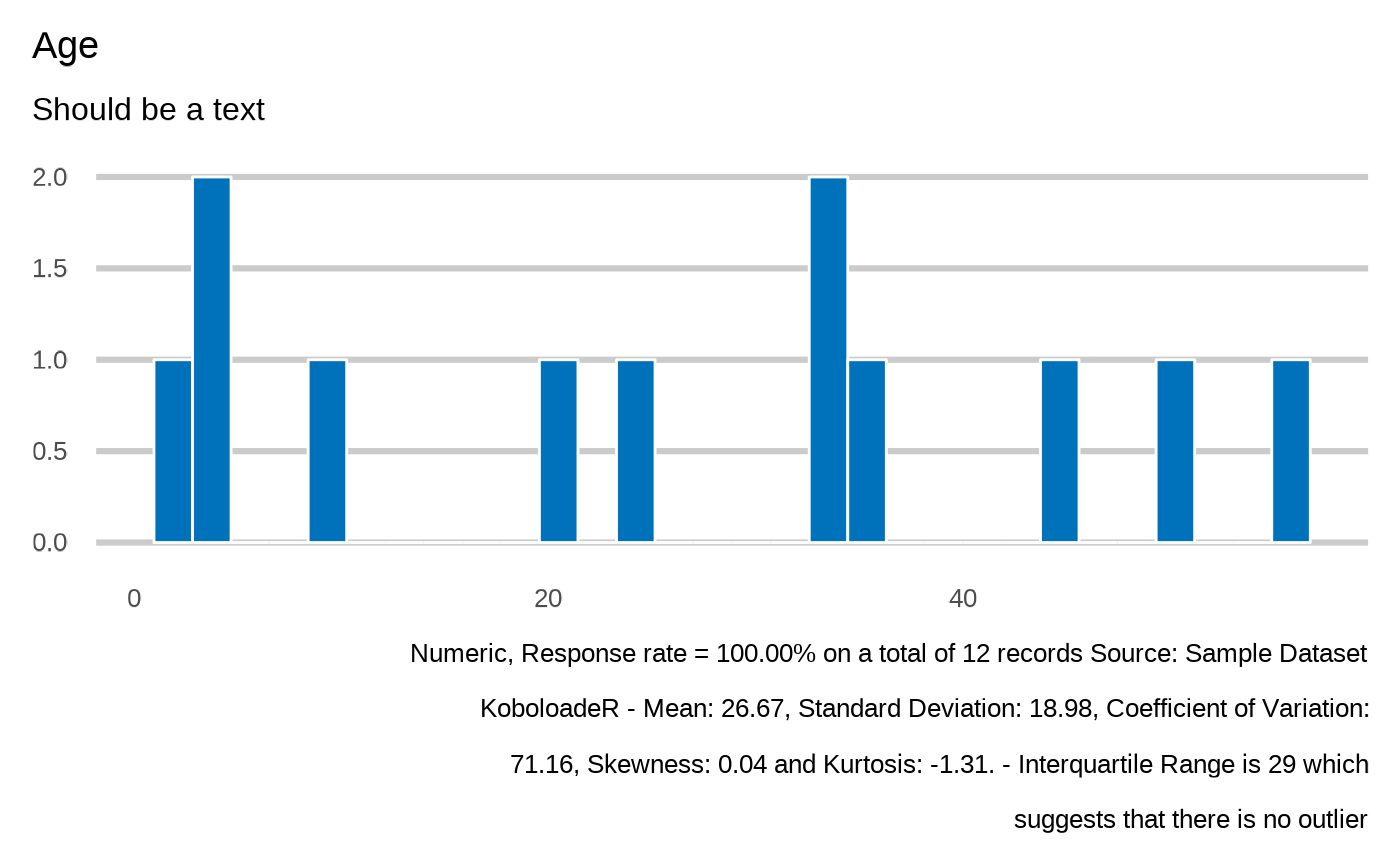
Plotting Open Text variable
dico <- kobo_dico( xlsformpath = system.file("sample_xlsform.xlsx", package = "kobocruncher") )
datalist <- kobo_data(datapath = system.file("data.xlsx", package = "kobocruncher") )
plot_text(datalist = datalist,
dico = dico,
var = "profile.occupation",
showcode = TRUE)
#> Warning in tm_map.SimpleCorpus(., toSpace, "/"): transformation drops documents
#> Warning in tm_map.SimpleCorpus(., toSpace, "@"): transformation drops documents
#> Warning in tm_map.SimpleCorpus(., toSpace, "\\|"): transformation drops
#> documents
#> Warning in tm_map.SimpleCorpus(., tm::content_transformer(tolower)):
#> transformation drops documents
#> Warning in tm_map.SimpleCorpus(., tm::removeNumbers): transformation drops
#> documents
#> Warning in tm_map.SimpleCorpus(., tm::removePunctuation): transformation drops
#> documents
#> Warning in tm_map.SimpleCorpus(., tm::stripWhitespace): transformation drops
#> documents
#> Warning in tm_map.SimpleCorpus(., tm::stemDocument): transformation drops
#> documents
#> Warning in tm_map.SimpleCorpus(., tm::removeWords, tm::stopwords("english")):
#> transformation drops documents
#> Warning in tm_map.SimpleCorpus(., tm::removeWords, c("blabla1", "blabla2")):
#> transformation drops documents
#>
#> What's you occupation?
#> `plot_text(datalist, dico, "profile.occupation", datasource=params$datasource)`
#>
#> 
Plotting Select one variable with cross tabulation
dico <- kobo_dico( xlsformpath = system.file("sample_xlsform.xlsx", package = "kobocruncher") )
datalist <- kobo_data(datapath = system.file("data.xlsx", package = "kobocruncher") )
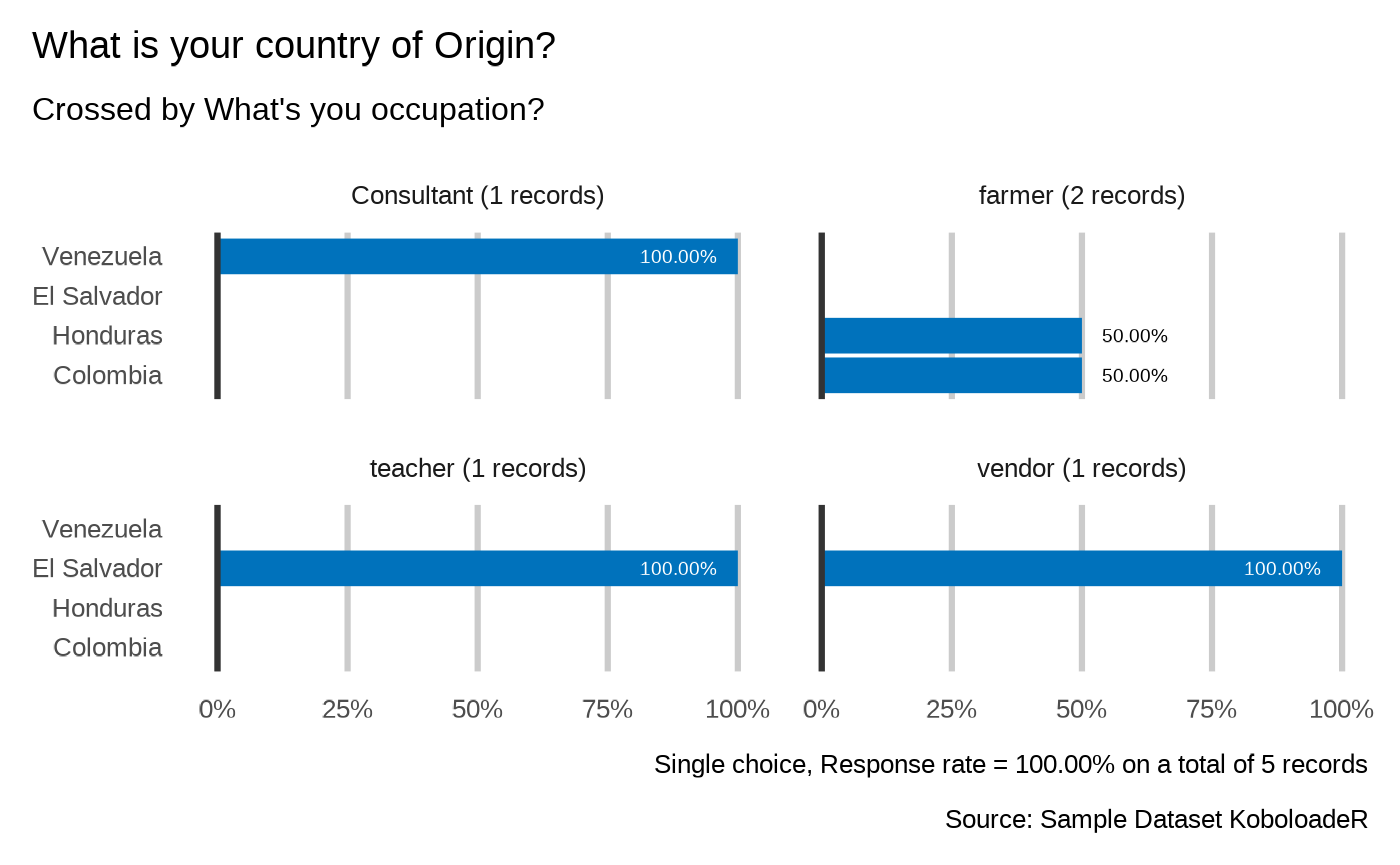
plot_select_one_cross(datalist = datalist,
dico = dico,
var = "profile.country",
by_var = "profile.occupation",
showcode = TRUE
)
#> What is your country of Origin?
#> `plot_select_one_cross(datalist, dico, var="profile.country", by_var="profile.occupation",datasource=params$datasource, n=4,n_by=4 )`
#>
#> 
## test if variable are not in the same frame...
plot_select_one_cross(datalist = datalist,
dico = dico,
var = "profile.country",
by_var = "members.sex",
n = 5,
n_by = 5,
showcode = TRUE
)Plotting Select multiple variable with cross-tabulation
dico <- kobo_dico( xlsformpath = system.file("sample_xlsform.xlsx", package = "kobocruncher") )
datalist <- kobo_data(datapath = system.file("data.xlsx", package = "kobocruncher") )
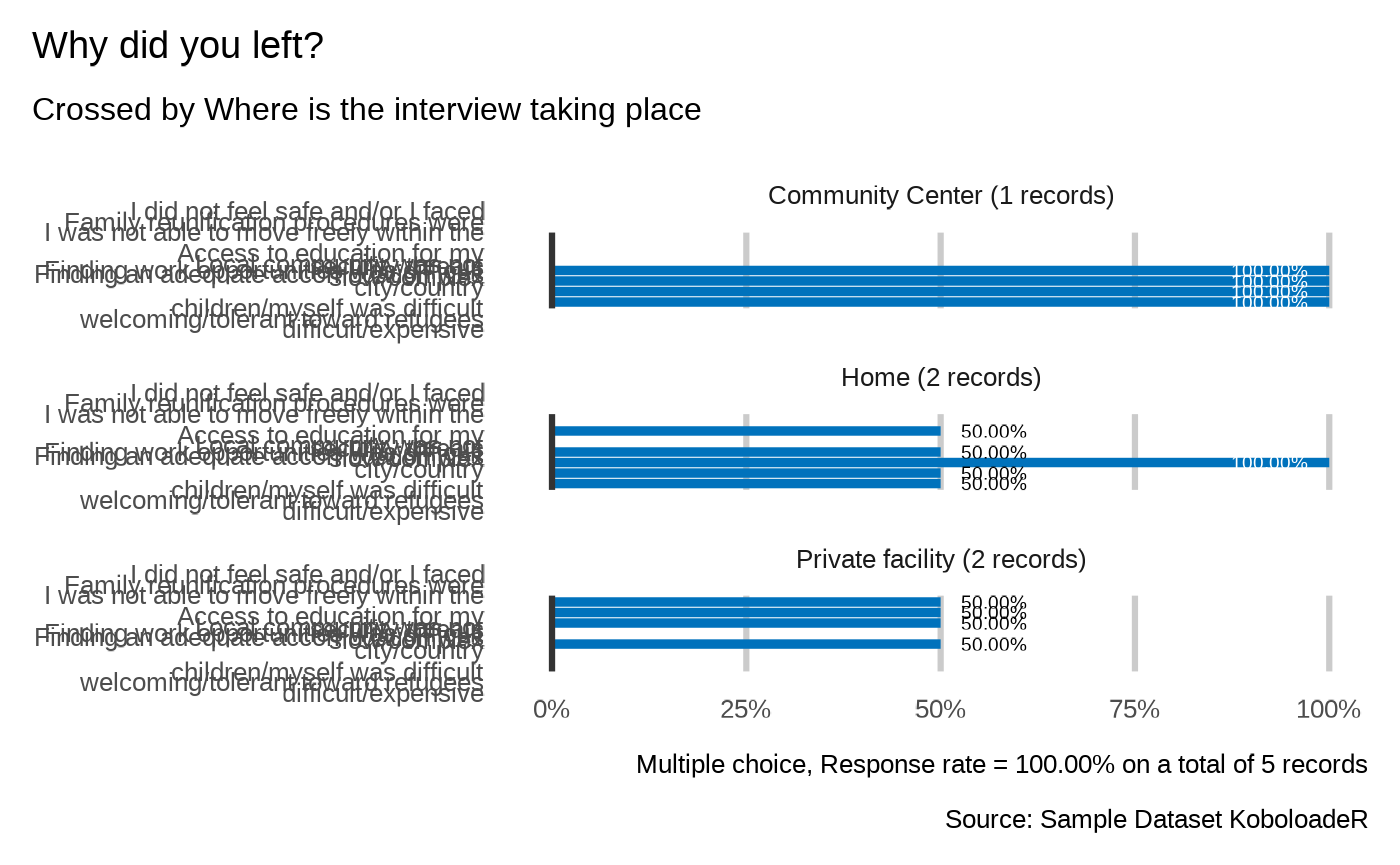
plot_select_multiple_cross(datalist = datalist,
dico = dico,
var = "profile.reason",
by_var = "location",
showcode = TRUE)
#> Why did you left?
#> `plot_select_multiple_cross(datalist, dico, var="profile.reason", by_var="location", datasource=params$datasource, n=7, n_by=3 )`
#>
#> 
## test lumping
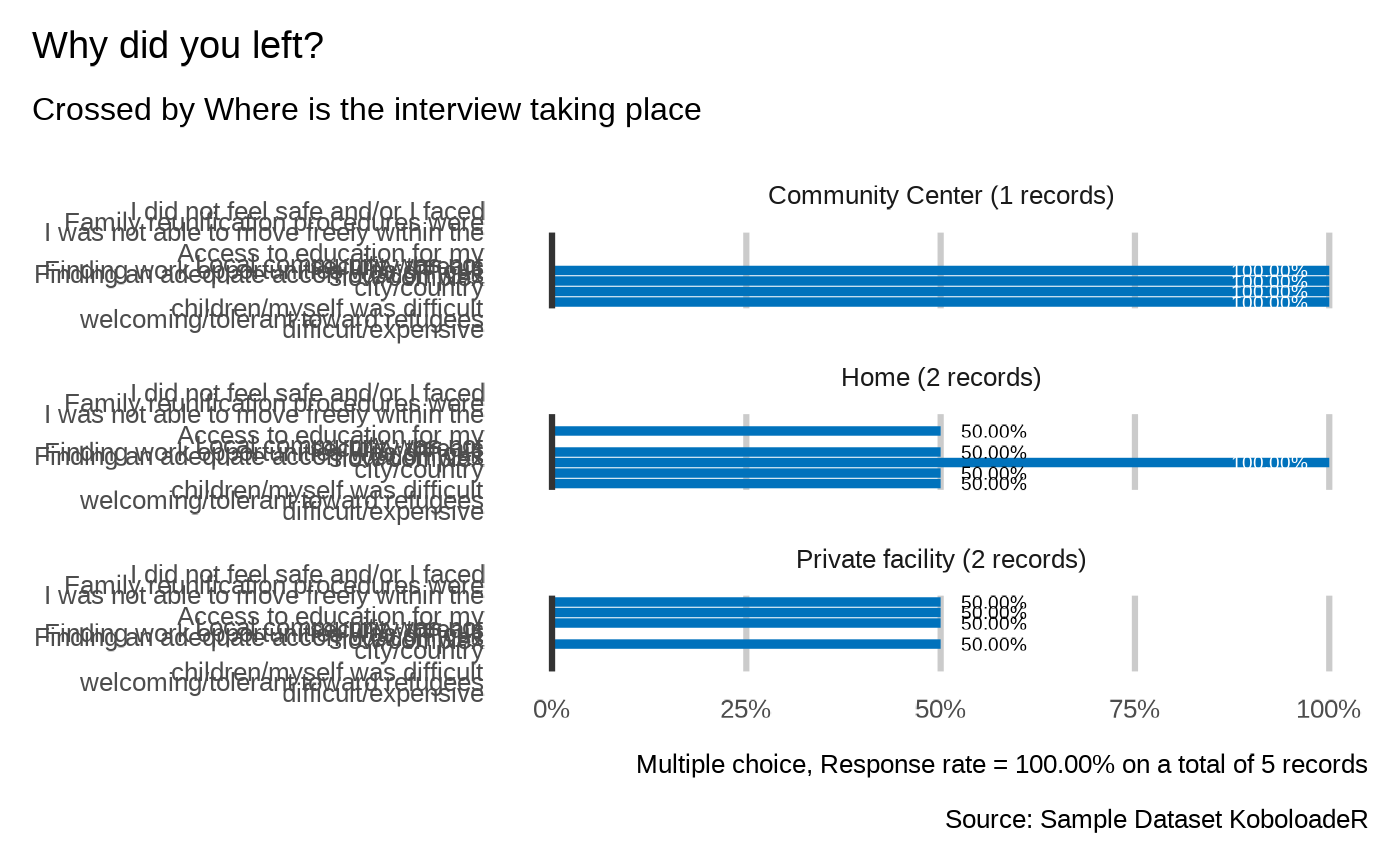
plot_select_multiple_cross(datalist = datalist,
dico = dico,
var = "profile.reason",
by_var = "location",
n = 4,
showcode = TRUE)
#> Why did you left?
#> `plot_select_multiple_cross(datalist, dico, var="profile.reason", by_var="location", datasource=params$datasource, n=4, n_by=3 )`
#>
#> 
Plotting Numeric variable with cross-tabulation
dico <- kobo_dico( xlsformpath = system.file("sample_xlsform.xlsx", package = "kobocruncher") )
datalist <- kobo_data(datapath = system.file("data.xlsx", package = "kobocruncher") )
plot_integer_cross(datalist = datalist,
dico = dico,
var = "members.age",
by_var = "members.sex",
showcode = TRUE)Plotting Correlation
dico <- kobo_dico( xlsformpath = system.file("sample_xlsform.xlsx", package = "kobocruncher") )
datalist <- kobo_data(datapath = system.file("data.xlsx", package = "kobocruncher") )
plot_correlation(datalist = datalist,
dico = dico,
var = "profile.occupation",
by_var = "profile.country",
datasource = NULL)
#> Warning in stats::chisq.test(formula$target, formula$tested): Chi-squared
#> approximation may be incorrect
#>
#> No significant association found between profile.occupation & profile.country (p.value :0.3505).Plotting Likert
dicolikert <- kobo_dico( xlsformpath = system.file("form_likert.xlsx", package = "kobocruncher") )
datalistlikert <- kobo_data(datapath = system.file("data_likert.xlsx", package = "kobocruncher") )
#> Warning: Unknown or uninitialised column: `_index`.
plot_likert(datalist = datalistlikert,
dico = dicolikert,
datasource = NULL,
scopei = "group_ei8jz33",
repeatvari = "main",
## getting the list_name and corresponding label
list_namei = "yk0td68"
)
#> Warning: `funs()` was deprecated in dplyr 0.8.0.
#> ℹ Please use a list of either functions or lambdas:
#>
#> # Simple named list: list(mean = mean, median = median)
#>
#> # Auto named with `tibble::lst()`: tibble::lst(mean, median)
#>
#> # Using lambdas list(~ mean(., trim = .2), ~ median(., na.rm = TRUE))
#> ℹ The deprecated feature was likely used in the kobocruncher package.
#> Please report the issue at
#> <https://github.com/Edouard-Legoupil/kobocruncher/issues>.
#> This warning is displayed once every 8 hours.
#> Call `lifecycle::last_lifecycle_warnings()` to see where this warning was
#> generated.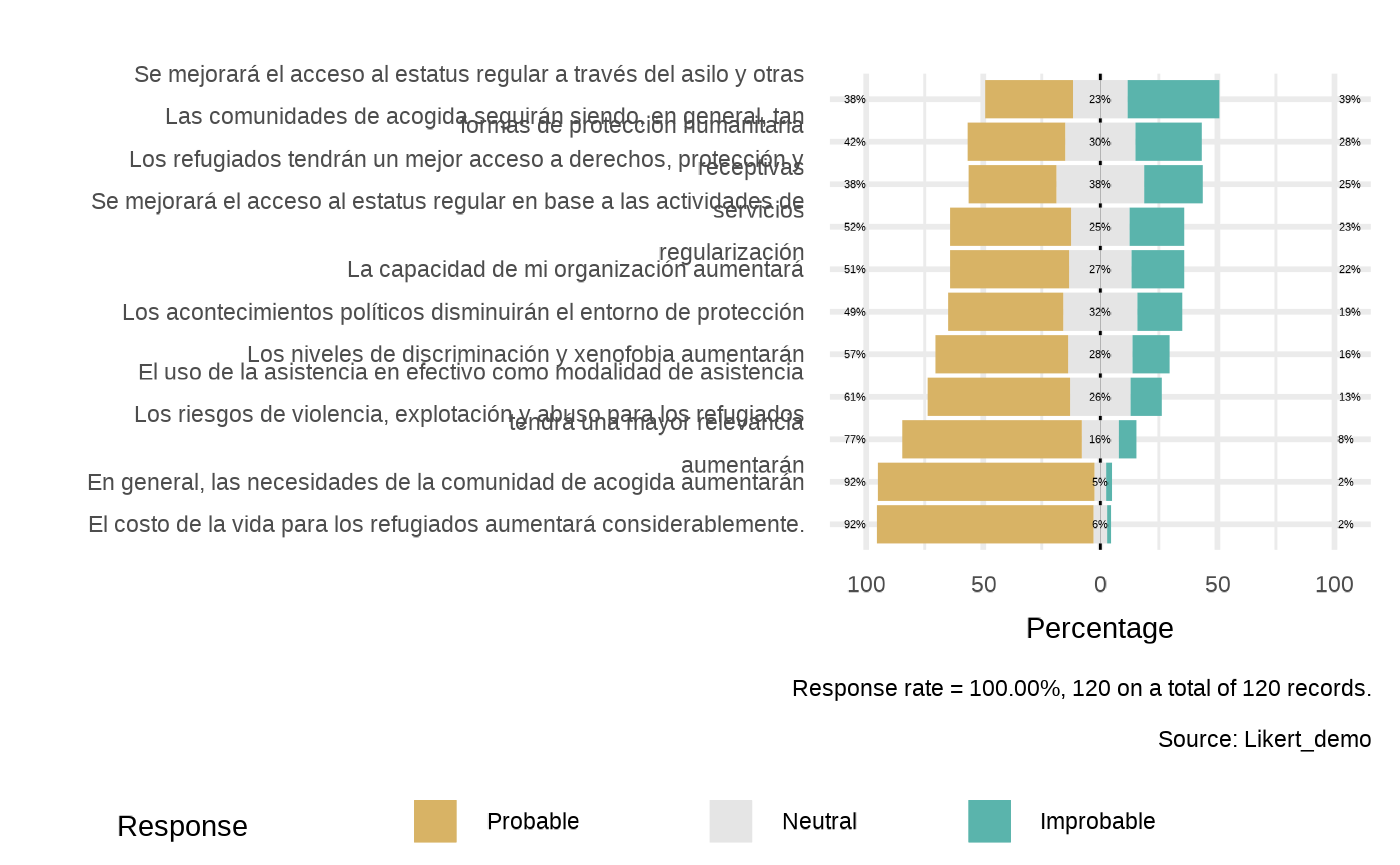
Plotting Header variable
dico <- kobo_dico( xlsformpath = system.file("sample_xlsform.xlsx", package = "kobocruncher") )
plot_header( dico = dico,
var = "profile.profile")
#> ------
#>
#>
#>
#> ## Respondant profile
# class(plot_header( dico = dico,
# var = "profile.profile"))
#
dput(plot_header( dico = dico,
var = "profile.profile"))
#> ------
#>
#>
#>
#> ## Respondant profile
#>
#> NULL
#
message(plot_header( dico = dico,
var = "profile.profile"))
#> ------
#>
#>
#>
#> ## Respondant profile
#>
cat(plot_header( dico = dico,
var = "profile.profile"))
#> ------
#>
#>
#>
#> ## Respondant profile
print(plot_header( dico = dico,
var = "profile.profile"),
useSource = FALSE)
#> ------
#>
#>
#>
#> ## Respondant profile
#>
#> NULLReport generation
Crunching Variables based on a plan
dico <- kobo_dico( xlsformpath = system.file("sample_xlsform.xlsx", package = "kobocruncher") )
datalist <- kobo_data(datapath = system.file("data.xlsx", package = "kobocruncher") )
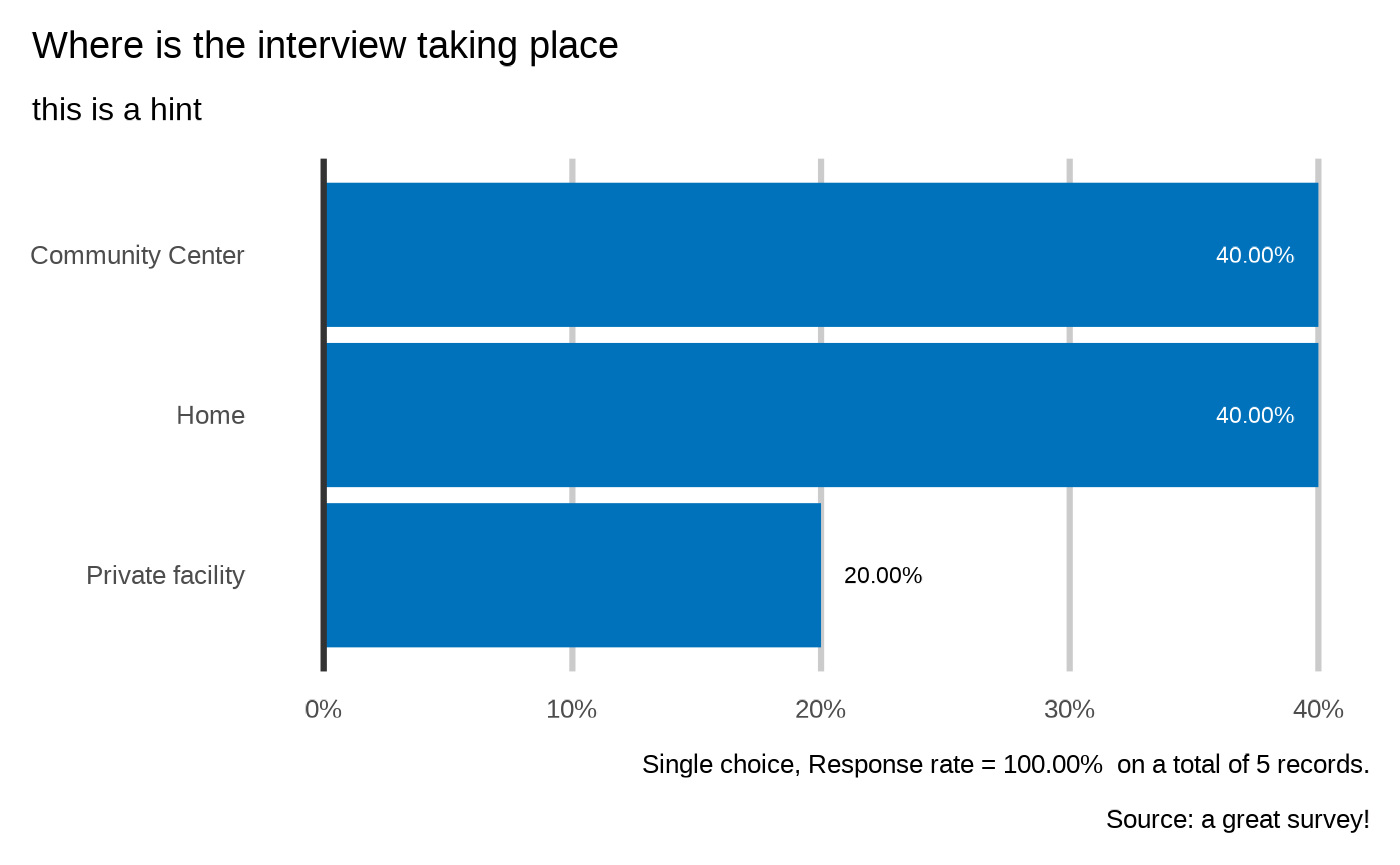
kobo_cruncher(datalist = datalist,
dico = dico,
datasource = "a great survey!")
#>
#> Where is the interview taking place
#> `plot_select_one(datalist, dico, "location", datasource = params$datasource, n = 5)`
#>
#> 
#> ------
#>
#>
#>
#> ## Respondant profile
#>
#>
#> What is your country of Origin?
#> `plot_select_one(datalist, dico, "profile.country", datasource = params$datasource, n = 5)`
#>
#>
#> Warning in tm_map.SimpleCorpus(., toSpace, "/"): transformation drops documents
#> Warning in tm_map.SimpleCorpus(., toSpace, "@"): transformation drops documents
#> Warning in tm_map.SimpleCorpus(., toSpace, "\\|"): transformation drops
#> documents
#> Warning in tm_map.SimpleCorpus(., tm::content_transformer(tolower)):
#> transformation drops documents
#> Warning in tm_map.SimpleCorpus(., tm::removeNumbers): transformation drops
#> documents
#> Warning in tm_map.SimpleCorpus(., tm::removePunctuation): transformation drops
#> documents
#> Warning in tm_map.SimpleCorpus(., tm::stripWhitespace): transformation drops
#> documents
#> Warning in tm_map.SimpleCorpus(., tm::stemDocument): transformation drops
#> documents
#> Warning in tm_map.SimpleCorpus(., tm::removeWords, tm::stopwords("english")):
#> transformation drops documents
#> Warning in tm_map.SimpleCorpus(., tm::removeWords, c("blabla1", "blabla2")):
#> transformation drops documents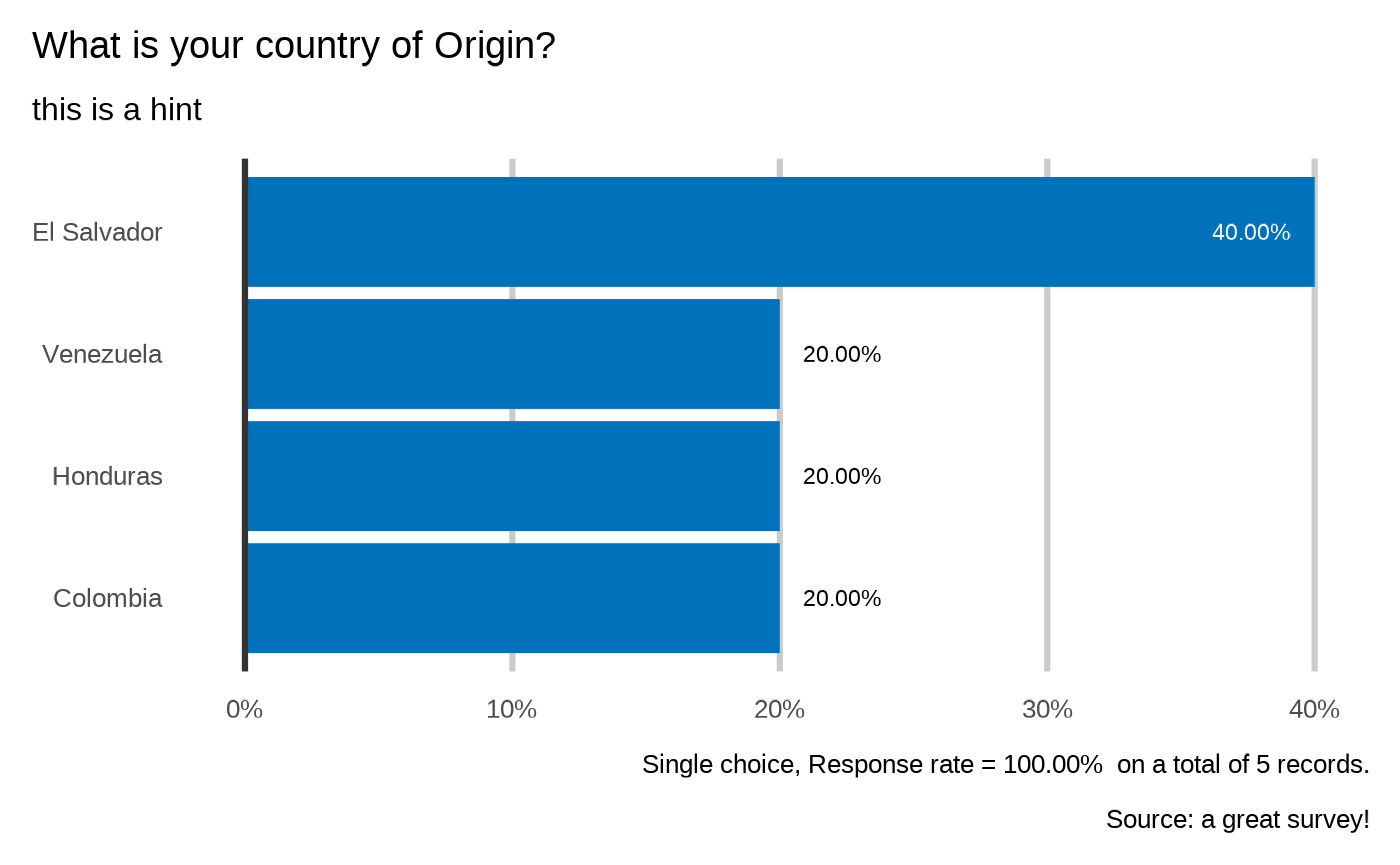
#>
#> What's you occupation?
#> `plot_text(datalist, dico, "profile.occupation", datasource=params$datasource)`
#>
#> 
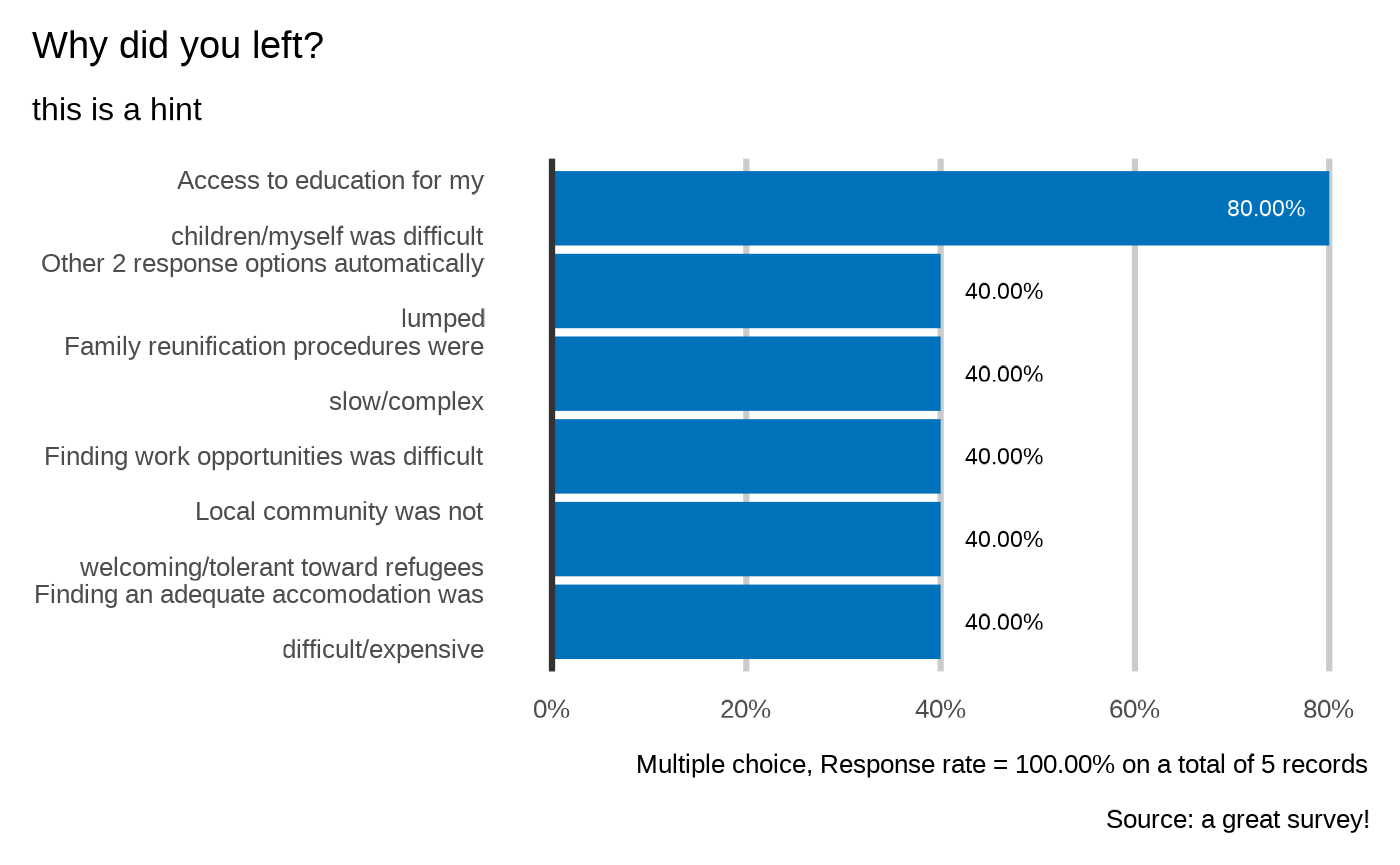
#> Why did you left?
#> `plot_select_multiple(datalist, dico, "profile.reason", datasource=params$datasource, n=5)`
#>
#> 
#> What's the size of your household?
#> `plot_integer(datalist, dico, "profile.HHSize", datasource=params$datasource)`
#>
#>
#> `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.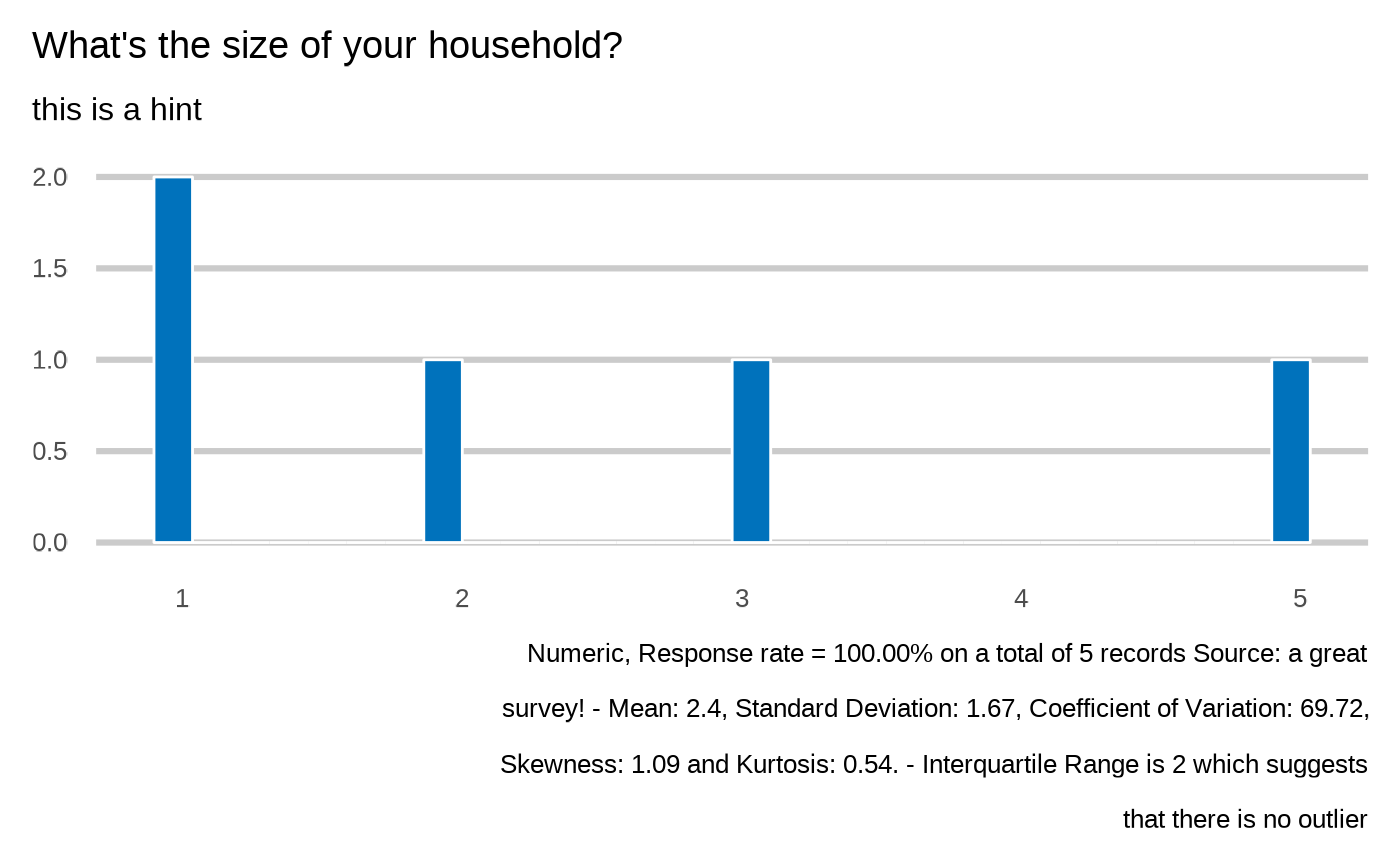
#> Age
#> `plot_integer(datalist, dico, "members.age", datasource=params$datasource)`
#>
#>
#> `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.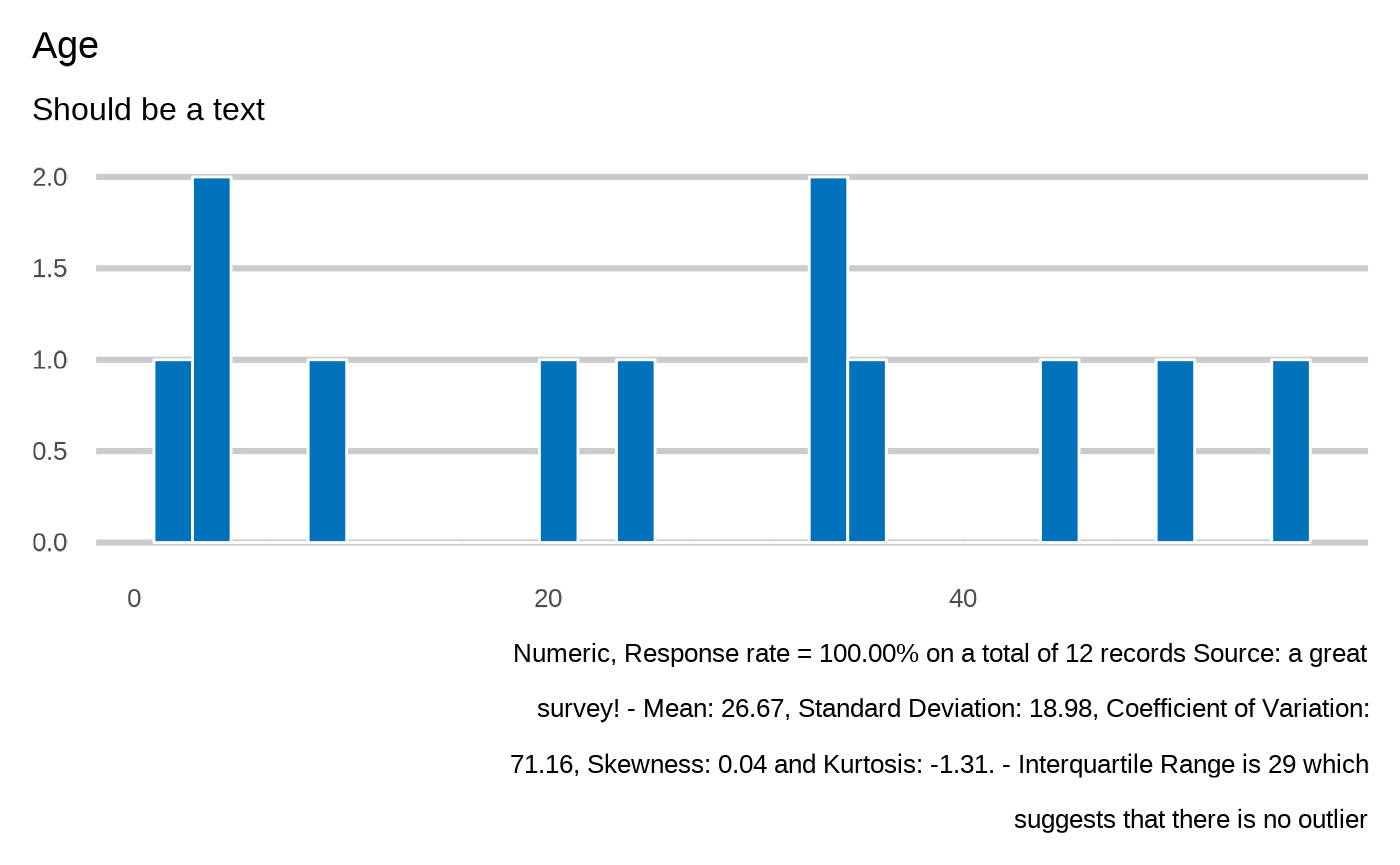
#>
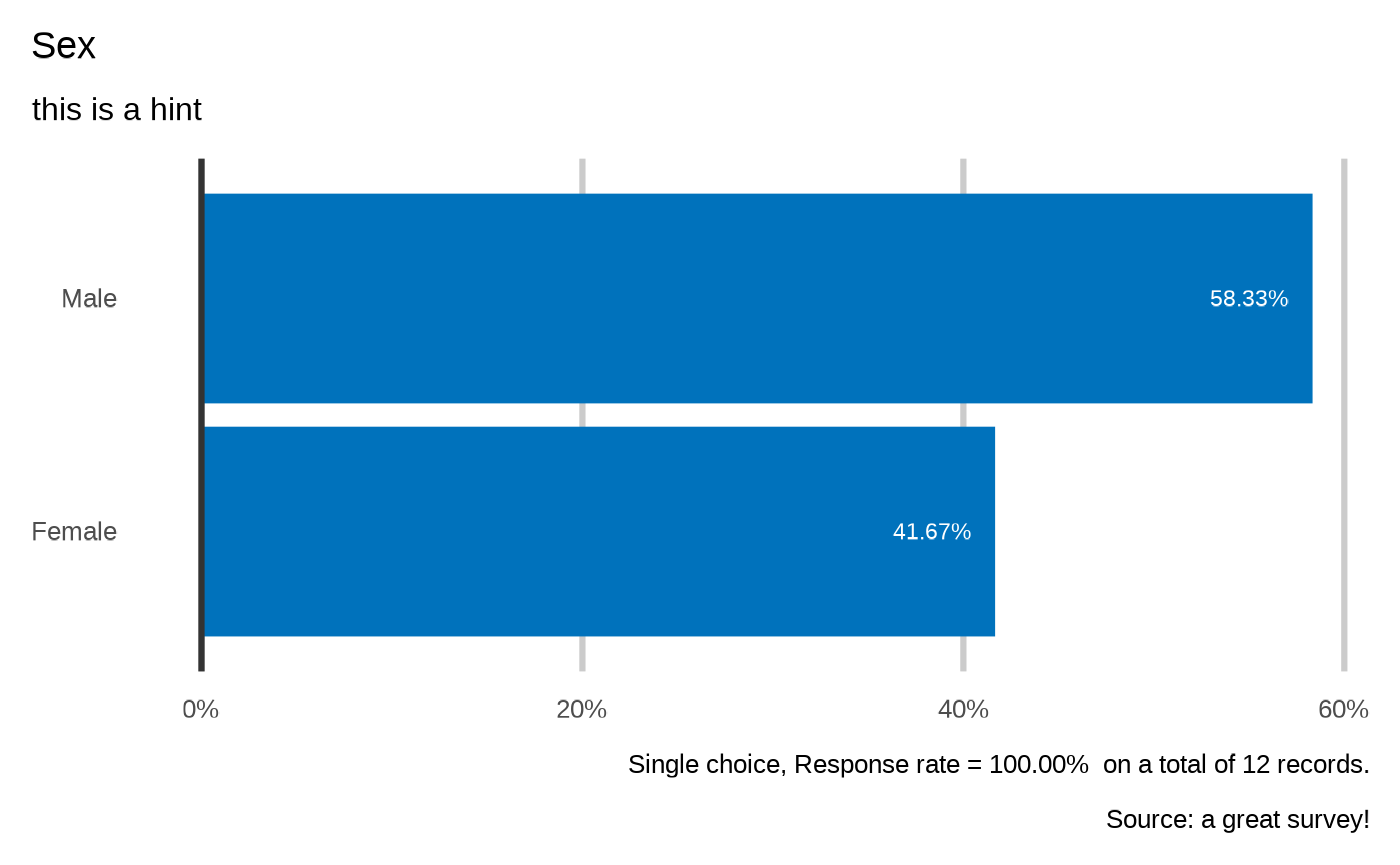
#> Sex
#> `plot_select_one(datalist, dico, "members.sex", datasource = params$datasource, n = 5)`
#>
#> 
Crunching Likert componnents
dicolikert <- kobo_dico( xlsformpath = system.file("form_likert.xlsx", package = "kobocruncher") )
datalistlikert <- kobo_data(datapath = system.file("data_likert.xlsx", package = "kobocruncher") )
#> Warning: Unknown or uninitialised column: `_index`.
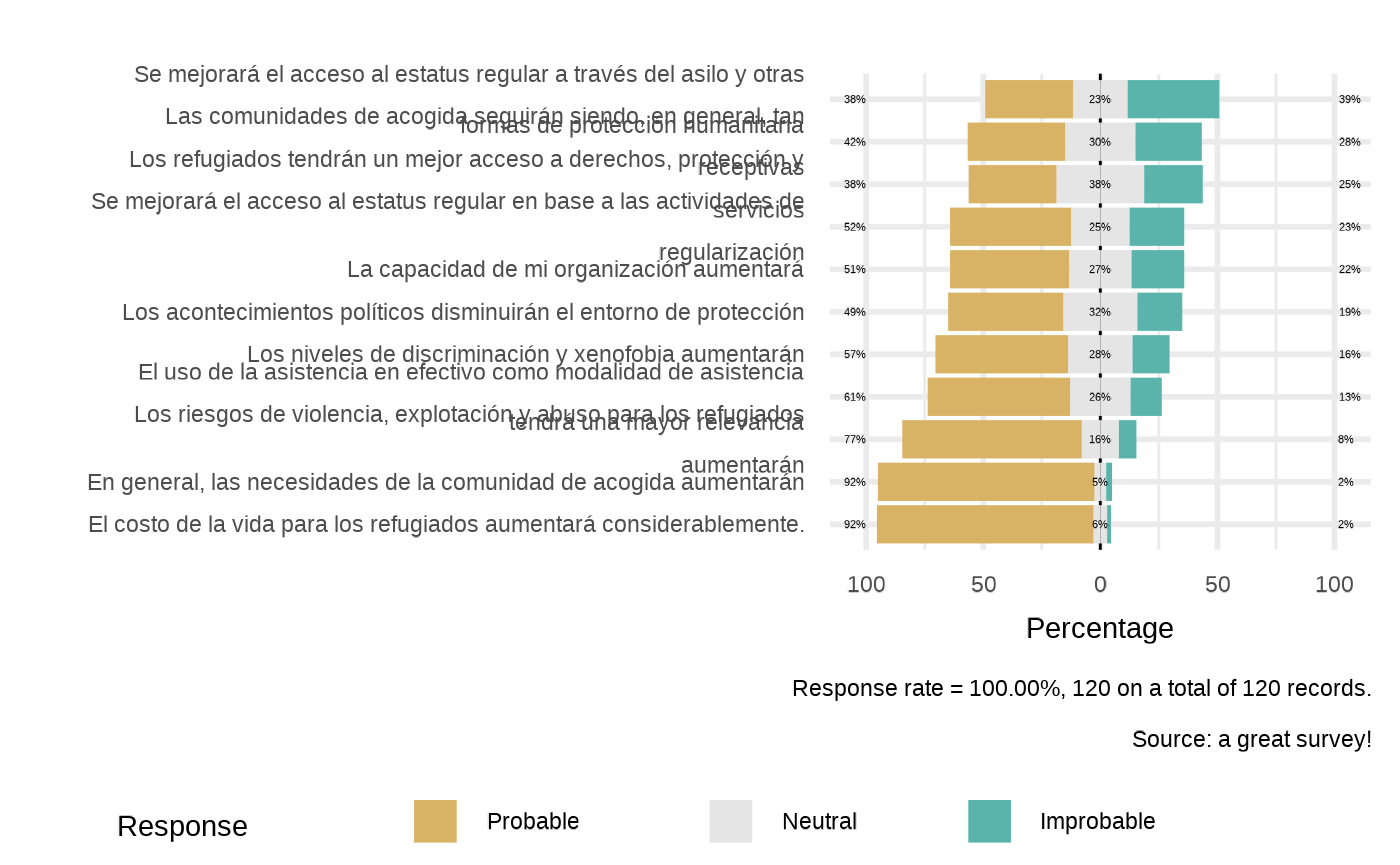
kobo_likert(datalist = datalistlikert,
dico = dicolikert,
datasource = "a great survey!")
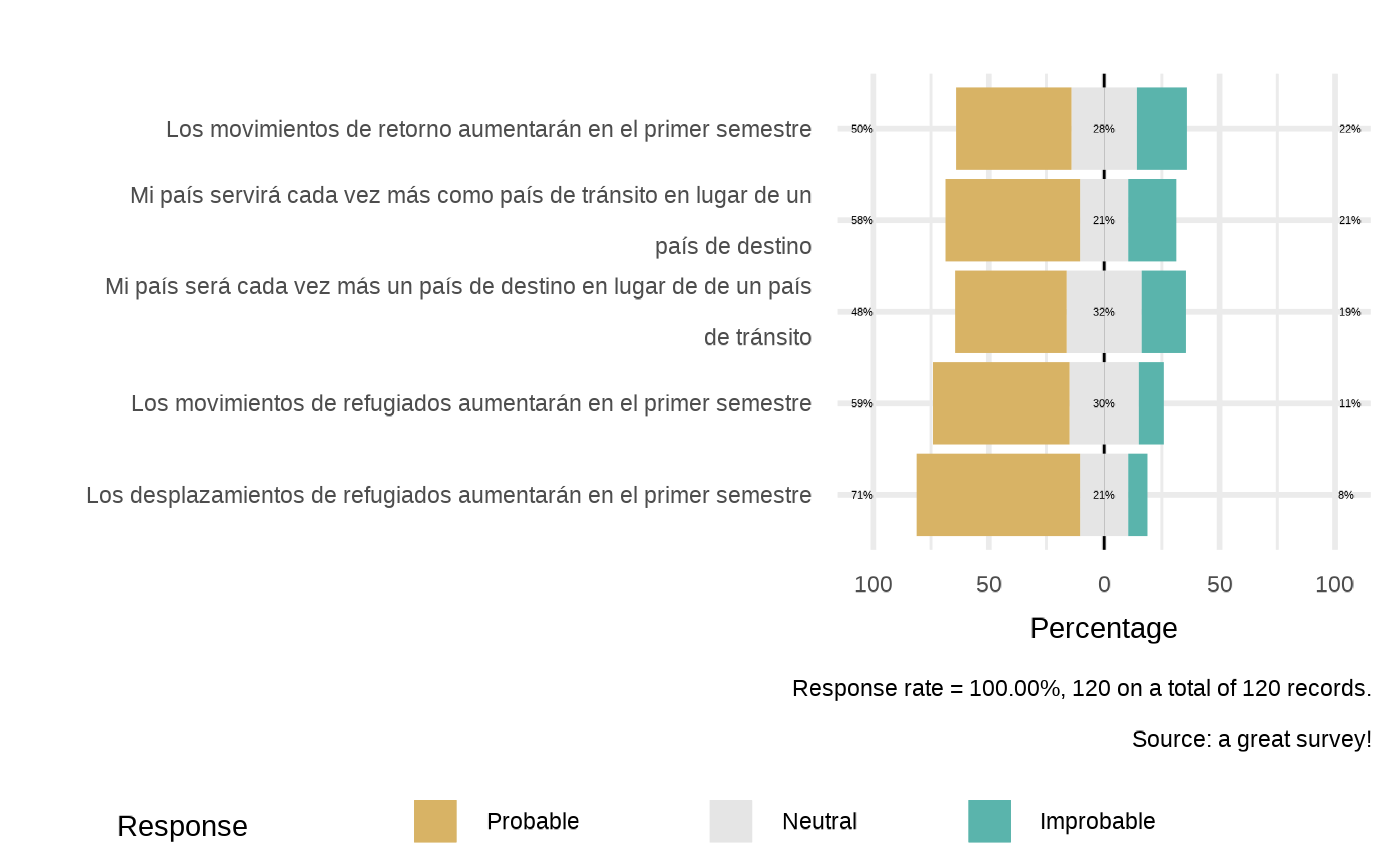
#> 3 groups of likert questions in the form`plot_likert(datalist, dico, scopei="group_ei8jz33", list_namei="yk0td68", repeatvari="main",datasource=params$datasource)`
#>
#> 
#> `plot_likert(datalist, dico, scopei="group_pm0cj55", list_namei="yk0td68", repeatvari="main",datasource=params$datasource)`
#>
#> 
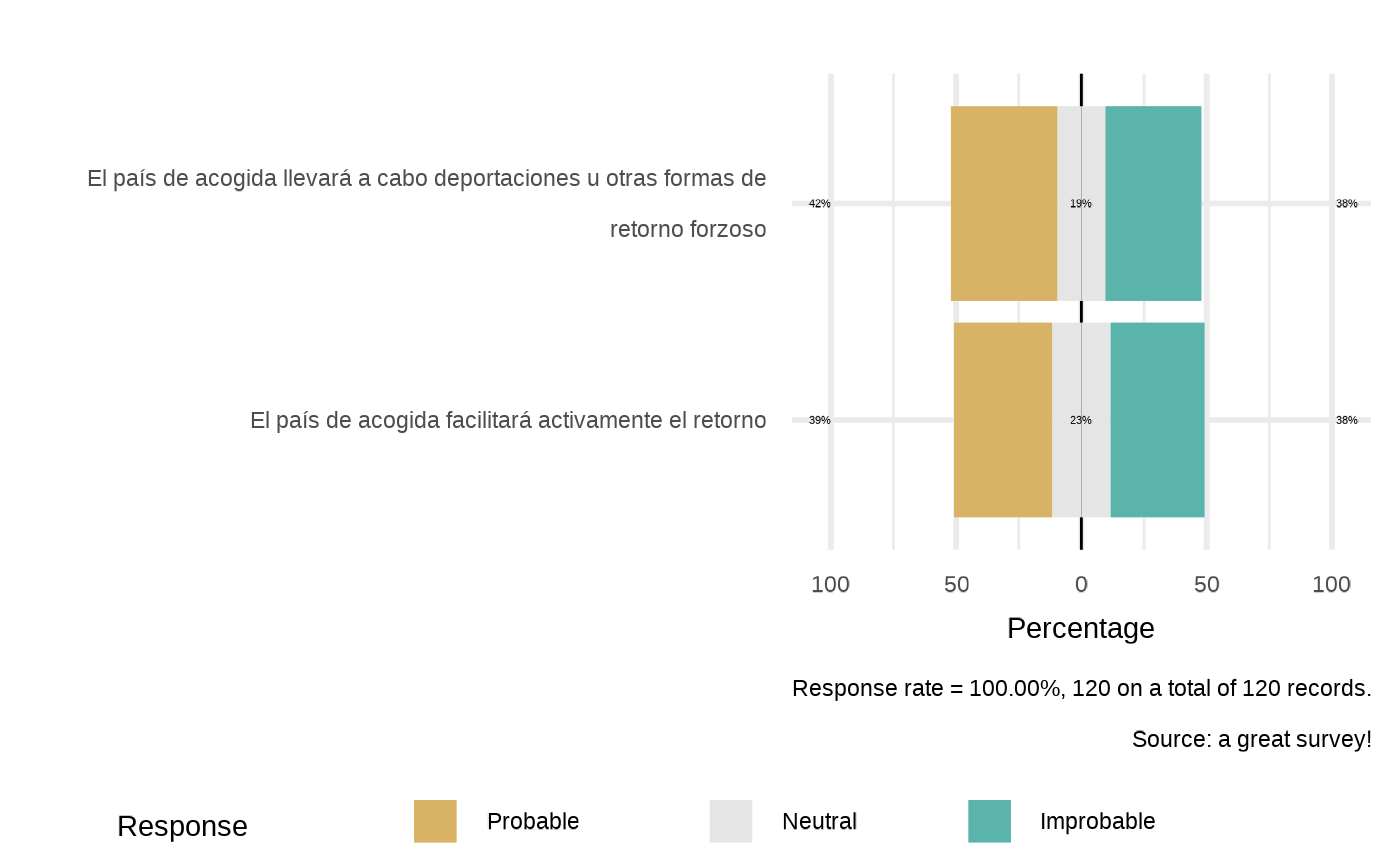
#> `plot_likert(datalist, dico, scopei="group_wc0ig44", list_namei="yk0td68", repeatvari="main",datasource=params$datasource)`
#>
#> 
Archive files in RIDL
### Example used for each template
## Time to archive your work once done!!
# namethisfile = basename(rstudioapi::getSourceEditorContext()$path )
# if( params$publish == "yes"){
# kobo_ridl(ridl = params$ridl,
# datafolder = params$datafolder,
# form = params$form,
# namethisfile = namethisfile ,
# visibility = params$visibility,
# stage = params$stage) }
Report Template A for Automatic Data Exploration
# template_1_exploration(datafolder= "data-raw",
# ridl = "ridlproject",
# data = "data.xlsx" ,
# form = "form.xlsx",
# datasource = "Study name reference",
# publish = "no",
# republish = "no",
# visibility = "public",
# stage = "exploration_initial",
# language = "",
# folder = "Report")Report Template B for Joint Data Interpretation Session
The second template is used following the systematic data exploration. It will generate a PowerPoint presentation
See a more detailed presentation of that step here: https://www.youtube.com/watch?v=0jE-Y7g88K4&feature=youtu.be&t=2305
#' Second Template to prepare a presentation for the Joint Data Interpretation Session
#'
# usethis::use_rmarkdown_template(
# template_name = "template_2_interpretation",
# template_dir = NULL,
# template_description = "Joint Data Interpretation",
# template_create_dir = TRUE
# )Report Template C for Note taking
The third template can be used in a similar way than the presentation template. It will generate a word document in order to take note.
An automatic table of content is generated but might required to be refreshed after the word document creation
#' Report Template 3 for Dissemination and Data Story Telling Template
#' The last template can be used to take note of the data interpretation session.
#' It will generate a PDF or an paginated HTML page
# usethis::use_rmarkdown_template(
# template_name = "template_C_notes",
# template_dir = NULL,
# template_description = "Note taking",
# template_create_dir = TRUE
# )Report Template D for Dissemination and Data Story Telling Template
The last template can be used to build the final report. It includes some instructions and guidance on how to organize the content to increase your audience
It will generate a PDF or an paginated HTML page
#' Report Template 3 for Dissemination and Data Story Telling Template
#' The last template can be used to take note of the data interpretation session.
#' It will generate a PDF or an paginated HTML page
# usethis::use_rmarkdown_template(
# template_name = "template_D_dissemination",
# template_dir = NULL,
# template_description = "Data brief and Story Telling",
# template_create_dir = TRUE
# )